The key to maximizing the value of machine learning models over time lies in continuously monitoring and retraining them. As incoming data changes, model performance deteriorates if the models are not retrained to adapt to the new data. This concept is known as model drift, which refers to the degradation in model performance over time. To counter model drift, companies need to retrain their models by including new, relevant data.
In this comprehensive guide, we will explore what model retraining is, why it is required, when models should be retrained, how much data should be used, retraining techniques, real-world examples, best practices, and tools for automated retraining.
What is Model Retraining?
Model retraining refers to the process of updating an already deployed machine learning model with newer data. The goal of retraining is to ensure that models continue making accurate predictions on real-world data.
Retraining tunes the existing model parameters so that the model provides healthier outputs. The parameters and variables used in the original model remain the same. Only the model‘s understanding of input data changes through retraining.

For instance, a churn prediction model may be retrained periodically to incorporate new customer behaviors. This enables the model to adapt to evolving customer trends.
Model retraining can be performed manually or automated as part of MLOps pipelines. Monitoring model performance and retraining regularly is referred to as Continuous Training in the MLOps methodology.
Overall, retraining improves model robustness and ensures sustained performance over time in dynamic, real-world conditions. Failing to retrain models can lead to losses of over $10 million per year for businesses as model accuracy drops.
Why Retrain ML Models?
There are two key reasons why retraining is necessary for machine learning models in production:
1. Concept Drift
Concept drift refers to changes in the relationship between input variables and target variables over time. For instance, factors that predicted credit risk in the past may not be as relevant today. When the concept being modeled itself evolves, models require retraining to realign predictions to the new concept.
A 2018 study on credit card fraud detection found that model accuracy dropped by over 20% within 3 months due to concept drift caused by new fraud tactics. Retraining boosted accuracy to original levels.
2. Data Drift
Data drift occurs when the statistical properties of input data change compared to the original training data. For example, customer preferences may shift from one product category to another. If the model is not retrained on newer customer data, its performance will degrade.
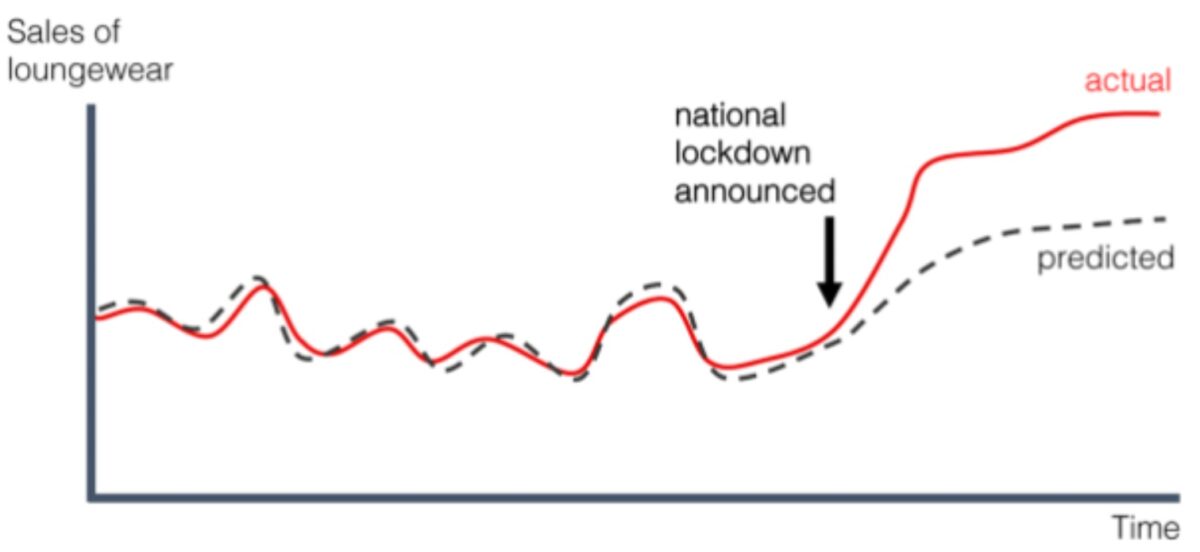
Data drift where distribution of inputs changes over time [Source: Neptune]
A 2022 analysis of product recommendation models in e-commerce found that retraining with latest data increased sales conversions by 8-12% compared to stale models.
Concept and data drift will inevitably occur in real-world environments. Retraining enables models to adapt so that the predictive power does not decline substantially. Companies need to monitor models and retrain them to counteract model drift proactively.
When Should Models Be Retrained?
Organizations can choose from two main approaches to determine retraining frequency:
Periodic Retraining
In periodic retraining, models are updated at fixed intervals, such as weekly or monthly. The retraining interval can be customized based on factors like data velocity and concept drift.
Faster changing domains like sentiment analysis may need more frequent retraining compared to more stable domains like equipment fault detection.
| Industry | Typical Retraining Frequency |
|---|---|
| Sentiment Analysis | Daily to Weekly |
| Recommender Systems | Daily to Monthly |
| Churn Prediction | Weekly to Monthly |
| Fraud Detection | Monthly to Quarterly |
Periodic retraining is simple to implement but can result in unnecessary retraining even when performance is satisfactory.
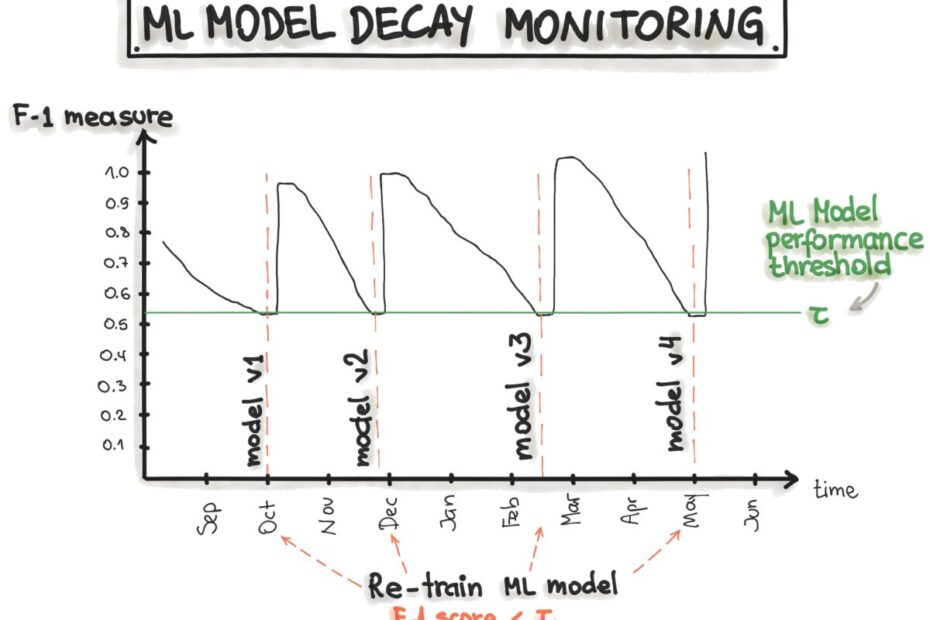
Retraining Triggers Based on Performance Drop
Here, retraining is triggered automatically when model performance drops below a defined threshold, as illustrated below:
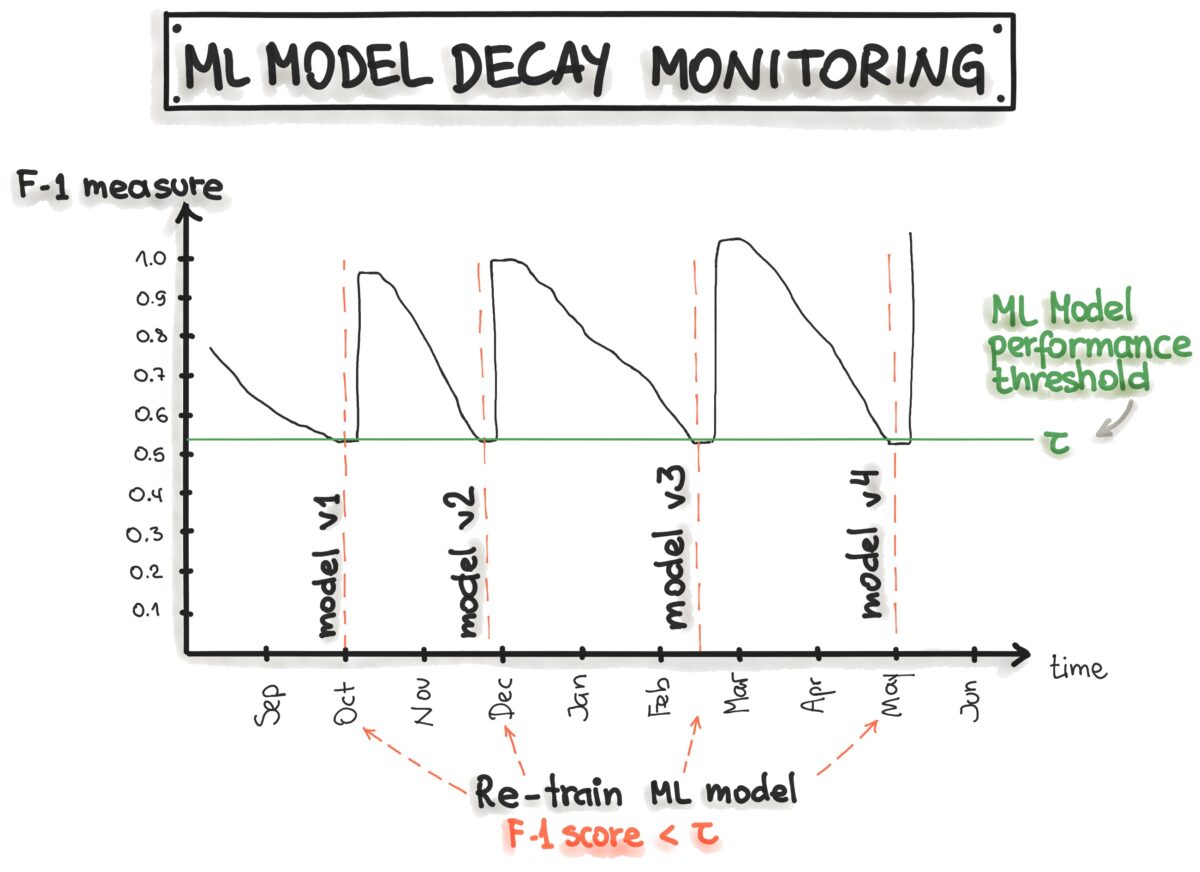
Thresholds on performance metrics can trigger automatic retraining [Source: ML-Ops]
Thresholds can be set on metrics like accuracy, AUC-ROC, precision etc. The major benefit is avoiding unnecessary retraining when the model is functioning well.
The challenge lies in identifying the optimal threshold to balance false positives and false negatives. A threshold of 5% drop in accuracy from peak performance is a reasonable starting point.
How Much Data Should Be Retrained?
When concept drift occurs, replacing the entire training dataset is recommended. This complete retraining is known as batch or offline learning.
However, full dataset retraining can be computationally expensive. For example, retraining a large deep learning image classification model on a million images can take weeks and cost thousands of dollars in compute resources.
Online learning provides a more efficient approach in many cases by continuously retraining with recent data through a sliding window mechanism.
For instance, models can be retrained hourly, daily or weekly on just the latest data while discarding older training examples. The sliding window size can be optimized to focus on representative and up-to-date data.
Online learning enables models to adapt rapidly at lower compute costs. However, batch retraining may still be required if online learning performance degrades significantly over time.
Hybrid Approach
A hybrid approach that combines periodic full retraining and continuous online learning can balance robustness and efficiency:
- Perform offline batch retraining quarterly or annually with full datasets
- Continuous online learning daily with sliding windows of latest data
This ensures the model does not diverge drastically from the core concept while also rapidly adapting to new data.
Retraining Techniques
Once the retraining approach is determined, the next key step is selecting the right retraining technique. Here are some options:
Parameter Tuning
Tuning hyperparameters like learning rate, regularization, batch size etc. on new data can improve model performance. This is fast and doesn‘t require changing model architecture.
Partial Retraining
Rather than retraining the full model end-to-end, only certain layers can be retrained which speeds up the process. For example, only retraining the final classifier layers in a deep learning model while freezing earlier layers.
Weighting Recent Data
Assigning higher weights to new data and lower weights to older data is a form of continuous online learning. This biases the model to adapt to recent data indicative of drift.
Model Stacking
Old and new models can be combined using ensembles or multi-model stacking techniques. This leverage strengths of both models on old and new data.
Architecture Search
Automated search can find if new model architectures further improve performance compared to retraining existing architecture.
The ideal techniques depend on the model, problem complexity, compute constraints and other factors. A/B testing different techniques is recommended.
Best Practices for Effective Model Retraining
Here are some tips to ensure an impactful and smooth retraining process:
-
Store training metadata – Log data schema, pre-processing steps, hyperparameters etc. to reproduce modeling pipelines during retraining.
-
Version models – Maintain versioned models for easy rollback in case retraining causes performance drops.
-
Retrain at optimal intervals– Balance retraining frequency, compute costs and model improvement.
-
Partially retrain – Retrain only certain model layers rather than full models to reduce compute.
-
Weight recent data – Boost significance of new data by assigning higher weights to counter concept drift.
-
Monitor continuously – Actively track metrics for drift detection and retrain before performance degrades severely.
-
Test extensively– Rigorously evaluate retrained models offline before deployment to ensure gains.
Key Factors to Consider
- Model complexity – Simpler models need more frequent retraining
- Data dynamics – Faster changing data requires more retraining
- Compute constraints – Balance retraining frequency and resources
- Severity of drift – Larger drifts need immediate retraining
- Model performance – Accuracy and business metrics should improve
Real-World Examples of Model Retraining
Here are some examples of how organizations retrain models in practice:
-
Ride-sharing apps like Uber and Lyft retrain demand forecasting models weekly based on latest traffic patterns, events and rider behavior. Periodic full retraining is done monthly.
-
E-commerce sites retrain recommender systems nightly using online learning on new customer interactions and purchases. Offline retraining happens during lower traffic periods.
-
OTT platforms like Netflix continuously A/B test personalized recommendation models trained on latest user activity and feedback.
-
Banks periodically retrain fraud detection models as new fraud tactics emerge over time requiring updated understanding.
-
Social media retrain content classification models hourly to adapt to emerging slang, themes and conversational nuances.
-
Manufacturers retrain predictive maintenance models quarterly or when performance degrades due to sensor drifts.
Tools for Automated Model Retraining
Manually monitoring and retraining models is not sustainable. MLOps platforms automate continuous model retraining:
CI/CD Pipelines
Tools like Jenkins and CircleCI allow configuring pipelines to trigger retraining workflows on schedules or based on model performance events.
Model Monitoring
Prometheus, Evidently and WhyLabs detect data and concept drift and can automatically trigger retraining when anomalies are found.
MLOps Orchestration
End-to-end MLOps platforms like Comet, Arize and Valohai provide capabilities to manage, orchestrate and monitor model retraining.
Model Management
Tools like ModelDB, MLflow and Verta help track model lineage, versions, experiments and performance metrics across retraining cycles.
Model Deployment
Tools like Seldon Core, BentoML and KFServing simplify scaling deployment of retrained models and routing traffic to new versions.
Automation enables rapid, efficient and scalable retraining processes. Retraining models manually will not scale as organizations scale their ML usage.
Key Takeaways
-
Model performance decays over time due to concept and data drift. Monitoring and retraining helps counter this model drift.
-
Retraining tunes models to new data without altering the core modeling approach.
-
Periodic and triggered retraining provide different retraining frequencies.
-
Online learning provides faster and cheaper retraining compared to full batch retraining.
-
The right retraining approach depends on the model, data, and business use case.
-
Automating retraining via MLOps is key for sustained model value in production.
Continuously retraining models by including incremental data is critical to maintain predictive power over time. Companies need to institutionalize retraining as part of model ops workflows to extract maximum return-on-investment from ML.
{kind=link}