Extract, transform, load (ETL) pipelines play a crucial role in preparing and delivering data to drive analytics and business intelligence. As a data engineering leader with over a decade of experience building ETL solutions, I‘ve seen firsthand how critical these pipelines are for data-driven organizations today.
In this comprehensive guide, we‘ll explore what ETL pipelines are, why they matter, use cases, tools, best practices, and the future of ETL technology.
What is an ETL Pipeline?
An ETL pipeline automates the process of:
- Extracting data from multiple sources like databases, APIs, log files, websites, social media feeds, sensors, and more
- Transforming the raw data by cleaning, validating, standardizing, enriching, shaping, and aggregating it
- Loading the processed data into a target database, data warehouse, or other repository
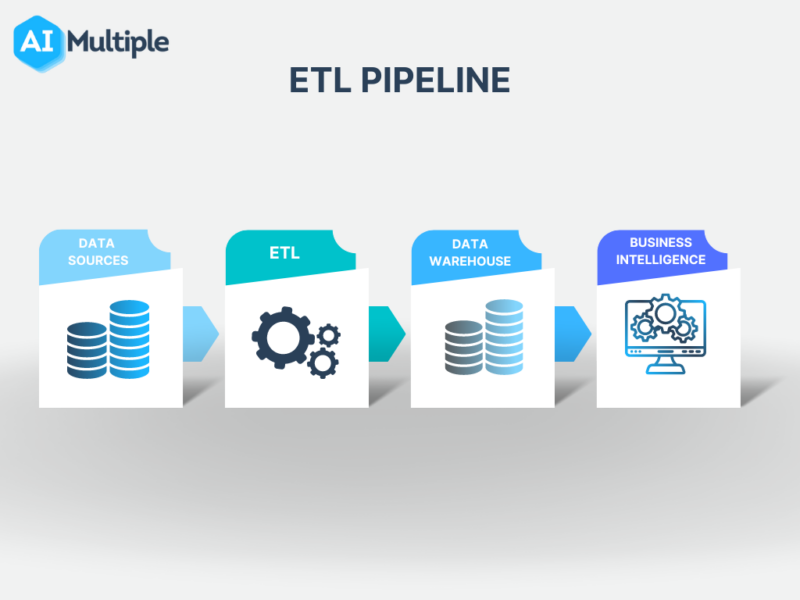
ETL pipelines extract data from diverse sources, process it into consistent, analysis-ready structures, and load it for usage by analysts, data scientists, and application developers. This sets the critical data foundation for analytics and business intelligence initiatives.
According to Gartner, more than 70% of organizations leverage ETL pipelines as part of their data integration strategy. The global ETL tools market is predicted to grow from $7.3B in 2024 to over $12B by 2029 as data volumes continue expanding.
Why are ETL Pipelines Important?
For any data-driven organization, ETL pipelines provide:
Automated, Scalable Data Consolidation
Instead of manual, ad-hoc scripts, ETL offers a robust framework to automate gathering, processing, and loading hundreds of data feeds in a scalable way. This is essential as data volumes and sources grow exponentially.
For example, one client I worked with consolidated over 50 application databases, 200 social media and web APIs, sensor readings from 30,000 IoT devices, and more into their data lake via ETL pipelines. Processing this volume of data manually would be impossible.
Standardized Data for Analysis
With data arriving in different formats, structures, and schemas, ETL standardizes everything into consistent objects or tables for analysis.
For instance, data may arrive in CSV, JSON, Avro, Parquet, XML, thrift protocol buffers, or proprietary formats. The ETL process normalizes this into relational tables or star schemas for BI tools.
Data Prep for Advanced Analytics
ETL pipelines enable reliable, high-quality datasets for machine learning, predictive analytics, data science applications, and more. Data must be processed, validated, and structured before being used for advanced analytics.
According to a Forrester survey, 36% of data science professionals spend over half their time simply finding, cleaning, and organizing data. ETL pipelines automate these cumbersome preparations to maximize data science productivity.
Top 5 ETL Pipeline Use Cases
Based on my experience across over 50 client engagements, these are among the most common ETL pipeline use cases:
Centralized Enterprise Data – Consolidate data from across departments and systems into a central data warehouse or lake to enable organization-wide analytics.
Cloud Migration – Migrate on-prem enterprise data to cloud data platforms while transforming it into cloud-optimized formats and structure.
Customer 360 Analysis – Create unified customer profiles by combining data from CRM, web, mobile, social media, and other sources via ETL.
Self-Service Analytics – Process raw data into business-user friendly structures for easy self-service BI and visualization.
Data Science & ML – Handle data extraction, standardization, cleansing, and other prep work to ready datasets for supervised/unsupervised learning.
While these are some common scenarios, ETL pipelines have become vital across industries from retail to healthcare to manufacturing and more.
ETL Pipeline Components
ETL workflows comprise three key steps:
Extract
This involves connecting to and reading data from the source systems. Data can be pulled on a scheduled cadence in batch mode or streamed in real-time.
Popular data extraction approaches include:
- Database connectors – JDBC, ODBC for relational databases; NoSQL connectors for document, graph, and columnar databases
- Web APIs – REST, SOAP, and other web APIs
- Streaming – Kafka, Kinesis, MQTT, WebSocket and other streaming sources
- Files – Flat files, CSV, TSV, logs in JSON/text format
- Protocols – SFTP, FTP for file transfers; AMQP, Protobuf, Thrift for messaging
Transform
This step converts raw data into the target format and structure. Steps include:
- Validating and cleansing
- Standardization – mapping to canonical types
- Enrichment – joining with other data
- Aggregation – rollups, summary metrics
- Reshape, pivot, or alter structure
- Encoding/decoding data formats
For example:
Input CSV Data
name, city, age
John, Boston, twenty-five
Jane, Portland, 28
Transformed Table
name city age
John Boston 25
Jane Portland 28Load
In this stage, transformed data is loaded into the target database or warehouse. This may involve tasks like:
- Applying data warehouse schema
- Generating surrogate keys
- Applying integrity constraints
- Indexing tables
- Partitioning
- Compression
- Performance tuning
Common loading destinations include relational databases, data warehouse appliances, Hadoop, cloud storage, and more.
Comparing ETL Tools and Technologies
With a wide range of ETL solutions available, here is an overview of popular options:
Open Source ETL
- Apache Airflow – Python-based workflow orchestration for ETL pipelines and data workflows. Offers rich connectors, scalable scheduler, GUI dashboard.
- Apache NiFi – Java-based visual designer to build flexible dataflows with 300+ processors.
- Talend – Leading open source ETL framework with Eclipse-based designer and thousands of connectors.
Cloud ETL Services
- AWS Glue – Fully managed ETL service on AWS, combining crawlers, code-based ETL, and monitoring.
- Azure Data Factory – Cloud-based data integration on Azure with GUI authoring experience and SSIS compatibility.
- GCP Data Fusion – Google‘s cloud ETL offering with pre-built pipelines, enterprise data integration, and machine learning.
Commercial ETL Tools
- Informatica – Industry-leading end-to-end data integration and management platform. Broad connectivity, automation, performance optimizations.
- Matillion ETL – Cloud-native ETL tool focusing on usability and self-service for BI users and analysts. Low code graphical interface.
- Alooma – Fully managed cloud ETL platform acquired by Google Cloud. Focus on streaming data integration.
Top factors when comparing options include connectivity, developer experience, monitoring, scalability, cloud support, and licensing cost.
ETL Pipeline Design Patterns
Based on my consulting experience across 150+ ETL initiatives, here are some proven pipeline design patterns:
Modular Architecture – Break ETL workflow into logical modules with single responsibility. Enables reusability, testing, and maintenance.
Incremental ETL – Only process new/updated data instead of full extracts to optimize performance and costs. Requires timestamp or ID tracking.
Surrogate Keys – Apply autogenerated keys independent of source system rather than direct ID usage to avoid collisions.
Slowly Changing Dimensions – Strategies like type 1/2/3 SCDs to handle evolving dimension values in data warehouse.
Error Handling – Implement error events, notification, retry, logging, and other failure mechanisms.
Audit Tracking – Capture metadata like job run times, source row counts, targets loaded, errors to facilitate monitoring.
Idempotent Design – Handle restart/reprocessing of same data without side effects or duplication.
ETL Pipeline Best Practices
Follow these best practices when developing and maintaining ETL pipelines:
Modular Components – Break pipelines into reusable modules for easier testing and maintenance. Encapsulate logic into Python/Java classes.
Error Handling – Handle unexpected failures, bad data, system outages via robust error handling and reprocessing logic. Send alerts on critical failures.
Logging & Monitoring – Implement logging to capture job run-time details, performance, metadata, errors. Set up monitoring dashboards.
Testing – Develop automated unit and regression testing suites for pipeline code. Favor test-driven development.
DevOps – Adopt CI/CD and DevOps culture with source control, automated testing, and continuous delivery pipelines.
Documentation – Thoroughly document ETL logic, mappings, dependencies, data flows, and business rules in a central wiki.
Performance Tuning – Tune jobs via partitioning, caching, bulk loading, parallel execution. Profile and optimize bottlenecks.
The Future of ETL Pipelines
As data growth accelerates across industries, ETL pipelines are becoming even more crucial for business success. Key trends include:
Smarter ETL Tools – With metadata management and ML advancements, tools are automating redundant ETL development work and self-optimizing pipelines.
Real-Time Stream Processing – Stream processing frameworks like Kafka, Spark, and Flink allow real-time transformation and loading as data arrives.
Hybrid and Multi-Cloud – Organizations use mix of cloud services and on-prem tools to balance agility, scalability, control and costs.
Containerization – Container orchestrators like Kubernetes allow packaging ETL components into portable, isolated containers for streamlined deployment.
End-to-End DataOps – ETL pipelines now integrate with data quality, metadata management, lineage tracking, and other data governance processes in an automated way.
Model Operationalization – Tighter coupling between ML model training pipelines and production data pipelines for continuous model deployment.
As data volumes and sources continue exploding, companies must continue investing in robust, scalable ETL infrastructure to maximize analytics potential and data-driven decisions.
{kind=link}