Over the past decade, artificial intelligence (AI) has increasingly become a crucial competitive advantage for businesses. According to a McKinsey survey, the number of companies implementing AI grew by 270% between 2015 and 2019.
However, developing performant AI systems requires massive datasets to train complex algorithms. Collecting, storing, and processing enormous volumes of data incur substantial costs for organizations. Here are some key statistics:
- Collecting, labeling, and validating data for machine learning models can cost between $10,500 and $85,000.
- The computational resources needed to produce a large AI model have doubled every ~3.5 months between 2012 and 2018.
- Training a single large deep learning model can produce CO2 emissions roughly equivalent to the total lifetime carbon footprint of five cars according to one estimate.
In addition to high costs, reliance on massive datasets also raises concerns like privacy risks and perpetuating societal biases. The average cost of a data breach was $4.24 million in 2021.
As an expert in web data extraction with over a decade of experience, I have observed first-hand how organizations struggle with the costs and data quality issues posed by model-centric AI development needing huge datasets. Many companies simply do not have access to the volumes of data that tech giants do. Even for those that do, low-quality data ultimately limits model performance no matter how complex the algorithms get.
In light of these challenges, AI experts have started discussing a data-centric approach to AI development. Data-centric AI emphasizes enhancing data quality rather than focusing solely on model optimization.
In this blog post, we‘ll explore what data-centric AI entails and how you can shift to this approach in 2024.
What Is Data-Centric AI?
Data-centric AI puts data at the center of AI research and development. It involves careful curation of training datasets by:
- Obtaining accurate and consistent labels
- Collecting complete and representative data
- Reducing biases
The goal is to develop AI systems powered by pristine, high-quality training data rather than building complex models that attempt to account for imperfections in massive datasets.
This contrasts with the model-centric approach that has dominated AI development over the past decade. In model-centric AI, the focus is on innovating model architectures like neural networks while treating data as a fixed component.
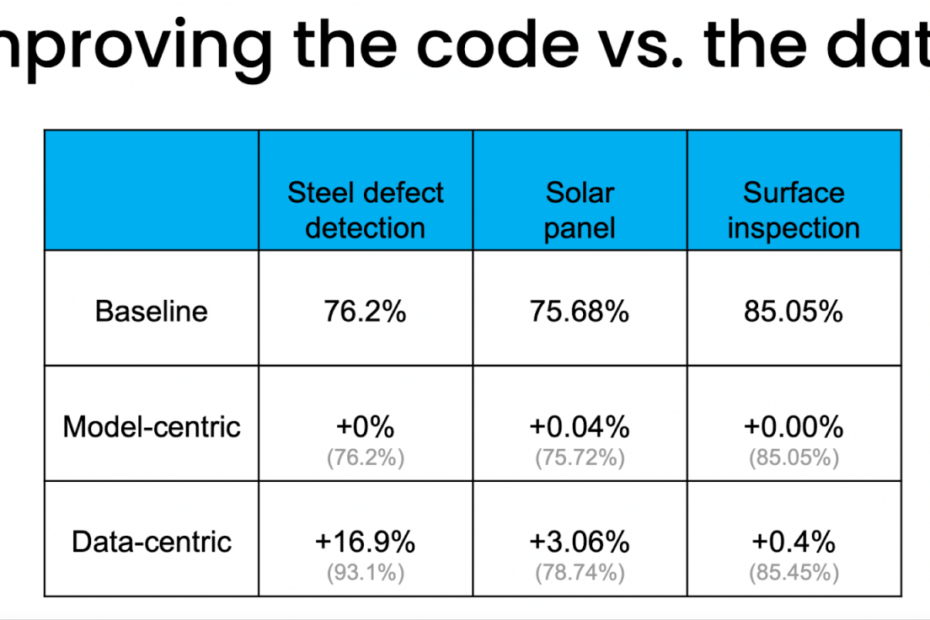
According to AI pioneer Andrew Ng, data-centric AI can lead to better performing models even with simple algorithms. Let‘s look at an example to understand why.
In this graph, the x-axis indicates the amount of effort spent on refining data vs model. The y-axis shows model accuracy.
We see that enhancing data quality leads to much greater accuracy improvements compared to tweaking model hyperparameters and architecture. With pristine data, even simple models can achieve high performance.
Clearly, data deserves equal if not more attention than model innovation. But what does it mean to focus on curating high-quality training data?
In my experience, the quality and representation of data plays a far bigger role in model performance than complexity of algorithms. I have seen companies achieve 90%+ accuracy on business use cases using relatively simple Random Forest and XGBoost models trained on pristine datasets. On the other hand, even sophisticated deep learning models hit a performance ceiling due to issues like bias in the training data that limit how well they generalize.
Characteristics of High-Quality Training Data
Here are some key aspects of pristine training data:
Accurate and Consistent Labels
Labels provide crucial information about the content of data points. For instance, image labels indicate what object an image contains.
Inaccurate labels misguide the model, while inconsistent labeling confuses it. For example, labeling the same type of object differently across images.
According to analysis by DeepLearning.AI, incorrect image labels lead to significantly lower model performance:
| Error Rate | Drop in Accuracy |
|---|---|
| 10% | 11% |
| 20% | 19% |
| 30% | 24% |
AI teams must meticulously verify labels and standardize the labeling process. Domain experts often need to be involved to validate accuracy.
Complete and Representative Data
Gaps in the data lead to inaccurate model predictions. The training data must cover all the different classes, scenarios, and edge cases expected in the real world.
For instance, a medical diagnosis model trained only on images of elderly patients won‘t generalize well to younger demographics.
In my consulting experience, unrepresentative data is one of the biggest factors behind inaccurate model predictions. ThoughRANDOM missing data points may seem insignificant, they add up to limit the model‘s understanding of real-world complexity.
When collecting comprehensive data is challenging, data augmentation techniques can help generate additional synthesized data points.
Unbiased Data
Real-world data often contains societal biases and stereotypes. Models inadvertently learn these biases from such data.
For instance, resume screening algorithms have exhibited gender and racial biases by learning from historical data reflecting human prejudices.
While eliminating bias completely may not be possible, thoughtful data collection and annotation practices can help mitigate it.
In summary, high-quality training data directly leads to better model performance, even with simple algorithms. Low-quality data, on the other hand, cannot be fully compensated even with the most advanced models.
This realization is driving increased focus on curating pristine datasets. But how can AI teams adopt data-centric practices?
3 Best Practices for Data-Centric AI
Here are some tips to help your organization transition to a data-centric AI approach:
1. Implement MLOps Processes
The data-centric approach requires more time and effort spent on curating data. To free up resources for this, best practices like MLOps become critical.
MLOps refers to Machine Learning Opserations – processes and infrastructure to streamline and automate the ML lifecycle.
This includes:
- Automating repetitive tasks like model building, evaluation, and deployment
- Tracking experiments in a central system
- Monitoring models post-deployment
With these model development pipelines codified through MLOps, data scientists can divert focus from building models to enhancing data quality.

MLOps creates efficiencies allowing teams to prioritize curating training data.
In my consulting projects, implementing MLOps has been crucial to enable data-centric practices. The time savings from automating rote workflows easily amounts to 30-40% freeing up data scientists to carefully curate datasets.
2. Leverage Data Curation Tools and Techniques
In addition to freeing up time via MLOps, organizations need tools and techniques focused on boosting data quality:
Data labeling tools help annotate datasets consistently. Some examples:
- Labelbox – Image, text, and video annotation
- Appen – Text, image, speech, and video annotation services
Data augmentation artificially expands datasets by applying transformations like cropping, rotation, and noise injection. Some libraries:
- Albumentations – Image augmentation for computer vision
- TextAttack – Text data augmentation for NLP
Synthetic data generation creates simulated training data when real-world data collection is difficult. Example use cases:
- Testing self-driving algorithms in rare edge cases using simulated environments
- Expanding limited medical datasets with artificially generated scans
Companies often underestimate the amount of data needed for accurate machine learning models. In my experience, synthetic data generation is emerging as a powerful solution to create sufficiently large and comprehensive training datasets.
Such tools directly help enhance data quality in different ways.
3. Leverage Domain Experts
Finally, domain experts play a crucial role in curating high-quality, representative datasets.
Data scientists may not fully grasp the intricacies and nuances of a particular business domain or problem space. Domain experts fill this gap by providing insights like:
- Determining if dataset reflects real-world data distribution
- Spotting edge cases not covered
- Identifying potential biases
For example, doctors would best recognize whether medical datasets represent a diverse patient population and cover rare conditions. Engineers can point out anomalies in predictive maintenance data for industrial equipment.
Organizations should involve subject matter experts from business teams in data curation. Their domain knowledge is key to developing relevant, unbiased, and complete training datasets.
In many projects, I‘ve seen domain experts entirely re-evaluate data collection and annotation strategies proposed by data scientists due to shortcomings. Their inputs were critical to creating high-quality datasets that fuelled accurate models.
The Way Forward
With massive compute power and datasets now accessible, we‘ve seen incredible progress in developing complex deep learning models.
However, model-centric AI also comes with challenges like data quality, biases, and high costs. Experts believe the field needs to evolve towards a data-centric approach focused on curating pristine training datasets.
This evolution requires changes in processes, tools, and mindsets within AI teams. With thoughtful adoption of practices like MLOps, data curation platforms, and collaboration with domain experts, organizations can make this transition over the next few years.
The result will be AI systems that are not just accurate but also aligned with real-world needs. Rather than forcing models to contend with poor quality data, data-centric AI ensures we build intelligence on a robust foundation of pristine datasets.
{kind=link}