
Have you ever wondered how chatbots are able to converse so naturally or translate languages instantly? How does Google surface extremely relevant results for your questions or YouTube recommend the perfect next video to watch? The key technology empowering these magical experiences is Natural Language Processing (NLP).
What Exactly is Natural Language Processing?
In simple terms, NLP refers to techniques that enable computers to understand, interpret and manipulate human languages for seamless interaction. But human languages evolved for humans afterall!
So teaching machines to decode convoluted linguistic rules, structures, context and meaning is incredibly complex. NLP aims to bridge this gap using a multifaceted approach spanning computer science, artificial intelligence and computational linguistics.
The goal is to analyze and eventually emulate the human ability to read, decipher intention, infer meaning and respond through language. This forms the basis for technologies like virtual assistants, semantic search, sentiment analysis in social media, automated customer support and much more.
Now that the stage is set, let‘s explore the key algorithms powering NLP behind the scenes…
The Core Components of a Typical NLP Pipeline
Typically processing natural language input involves the following stages:
Step 1: Text Normalization
Raw input text can be highly inconsistent. The same idea can be expressed using different words, sentence structures and languages. Normalization aims to clean and standardize textual data to minimize this variety.
For example, I love NLP and NLP rocks! convey essentially the same sentiment. By reducing the input to common terms, we simplify subsequent processing.
Step 2: Feature Extraction
The next step extracts useful attributes from normalized text required for analysis tasks.
- Tokenization: Breaking down sentences into fundamental units such as words, phrases and symbols.
- Lemmatization: Converting words into their root form by considering context and grammar (e.g. was becoming be)
- Vectorization: Representing tokens through numeric feature vectors capturing semantic meaning.
Together these techniques structure text convenient for machines to work with.
Step 3: Analysis Engine
This is the core stage where predictive NLP algorithms come into play. The structured input text gets passed into models like classification, topic modeling, summarization, translation and so on to extract answers for our questions.
Let‘s analyze some prominent NLP algorithms and their inner workings next!
Prominent Natural Language Processing Algorithms
NLP algorithms analyze linguistic structures and patterns in text to solve problems. Here I‘ll walk you through the most essential techniques:
1. Naive Bayes Classification
One of the simplest NLP algorithms is Naive Bayes. It works by calculating the probability of a piece of text belonging to a particular category. The calculation relies on the frequency of certain words occurring in the text to make this determination.
For instance, an article containing words like recession, unemployment and bankruptcy multiple times is likely about the economy. One discussing topics like touchdowns, referees and kickoffs belongs to sports.
The "naive" assumption it makes is that words occur independently. In reality, nearby words share contextual meaning. Yet surprisingly, this approach works very well! Naive Bayes is successfully used in sentiment analysis, spam filtering and authorship identification.
2. SVM (Support Vector Machines)
Unlike Naive Bayes, SVM is a more complex, robust algorithm commonly used for classification and regression tasks. It operates by plotting each data point in n-dimensional space (where n is number of features) and finding the hyper-plane that separates the classes best. New data points are then mapped into the same space and categorized based on which side of the gap they fall on.
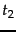
Visualization of SVM classifier (Image Source: Standford NLP Textbook)
SVM is great for text classification with high dimensional data. For short text, Naive Bayes often outperforms SVM.
3. Neural Networks
In recent years, neural networks have rapidly become a dominant approach for NLP by automatically learning patterns from large datasets. Here are some popular neural models:
- RNN – Recurrent Neural Networks specialize in processing sequences while retaining contextual information as they pass sequential data through looping connections.
- LSTM – Long Short Term Memory networks are an enhanced version of RNNs with more gates and memory states allowing them to learn longer context and term dependencies.
- CNN – Convolutional Neural Networks detect predictive local patterns and features across a sequence via sliding filters.
- Transformers – This new class of models eschews recurrence, instead applying attention mechanisms to capture relationships between all words simultaneously.
Together, RNN, CNN and self-attention in transformers have achieved state-of-the-art results across machine translation, sentiment analysis, text generation and other NLP tasks.
For instance, here‘s sample code for an RNN text classifier:
import tensorflow as tf
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(input_dim=1000, output_dim=64)
model.add(tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)))
model.add(tf.keras.layers.Dense(6, activation=‘relu‘))
model.add(tf.keras.layers.Dense(1, activation=‘sigmoid‘))
model.compile(loss=‘binary_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])This model would take input text sequences, pass them through an embedding layer to encode words as numeric vectors capturing meaning. These sequences go through forward and backward LSTM layers learning long range dependencies. Finally, this feeds into dense classifier layers to make a prediction. The result is able to capture semantic context much better than preceding approaches!
Let‘s look at two other popular unsupervised NLP techniques next.
4. Topic Modeling with LDA
Topic modeling refers to discovering hidden semantic themes contained within a collection of documents. The most common algorithm used is Latent Dirichlet Allocation (LDA).
It assumes each document covers multiple topics in different proportions. Each topic in turn dictates the frequency of certain words based on probability distributions. By scanning documents and word frequencies, LDA can shed light on those latent topics.
Topic models help explore large unfamiliar corpora for search, recommendations and analysis.
5. Word Embeddings (Word2Vec)
Word embedding is an incredibly useful innovation that maps words and phrases to numeric vector representations capturing their meaning. Using surrounding context windows, Word2Vec and GloVe algorithms efficiently encode vector relationships between words.
Some wonderful properties emerge. King – Man + Woman = Queen, for examples. Other vector arithmetic can solve analogies too. With enough data, meaningful patterns emerge reflecting extraordinary linguistic intelligence!
Today, contextualized embedding techniques lead state-of-the-art results in transfer learning. Sentence BERT generates dynamic token embeddings using transformer architectures. This captures sentence semantics rather than individual words alone leading to huge performance gains.
There are many more NLP algorithms powering common tools today – from speech recognition and synthesis to machine translation, optical character recognition, dialogue systems and beyond. But the techniques above form the core pillars of Natural Language Processing.
Current Challenges in NLP
Despite massive progress in recent years, NLP still faces some key challenges:
- Ambiguity – Human languages are often subjective and deeply nuanced. Without true comprehension, disambiguation remains difficult (e.g. sarcasm detection).
- Real World Knowledge – Humans have accumulated vast amounts of world knowledge and common sense through lifetime experience. Bestowing context awareness onto models continues to be hard.
- Reasoning – Truly understanding language requires complex reasoning about causality, events, emotions and speaker intent. Modern NLP models still struggle with logical deduction.
- Bias – Data encodes human prejudices. Identifying and eliminating societal biases like race, gender and age remains an immense challenge.
- Explainability – With deep neural models behaving like black boxes, explaining their internal rationale and building trust with users remains difficult.
Multilingual models that transfer learning across languages have shown promise tackling some of these problems. Advances in contextual word representations, graph embeddings, attention mechanisms and memory architectures are also helping. There‘s still a long way to go before machines can wholly comprehend elaborate human languages. But I remain excited by how far we have come!
I hope this guide gives you a firm grounding in the fundamentals behind NLP. Ping me with any other questions, and I‘l be happy to help!
{kind=link}