tags, using markdown for formatting.
The rapid evolution of deep learning has unlocked game-changing breakthroughs in computer vision, enabling transformative technologies like self-driving cars, medical imaging diagnostics, and facial recognition. However, training highly accurate computer vision models requires massive datasets of labeled images and videos, which can be prohibitively expensive and time consuming to collect and annotate manually. This is where synthetically generated visual data provides immense advantages.
In this comprehensive guide, we‘ll explore how synthetic images and videos can supercharge computer vision capabilities in 2024 and beyond. With over a decade of experience applying synthetic data on computer vision projects, I‘ll share my insights on how synthetic data can transform this space.
How Synthetic Data Unlocks the Potential of Computer Vision
Synthetic visual data offers several key benefits that can vastly improve computer vision systems compared to only using real-world images and videos:
1. Generate Large Labelled Datasets Faster and Cheaper
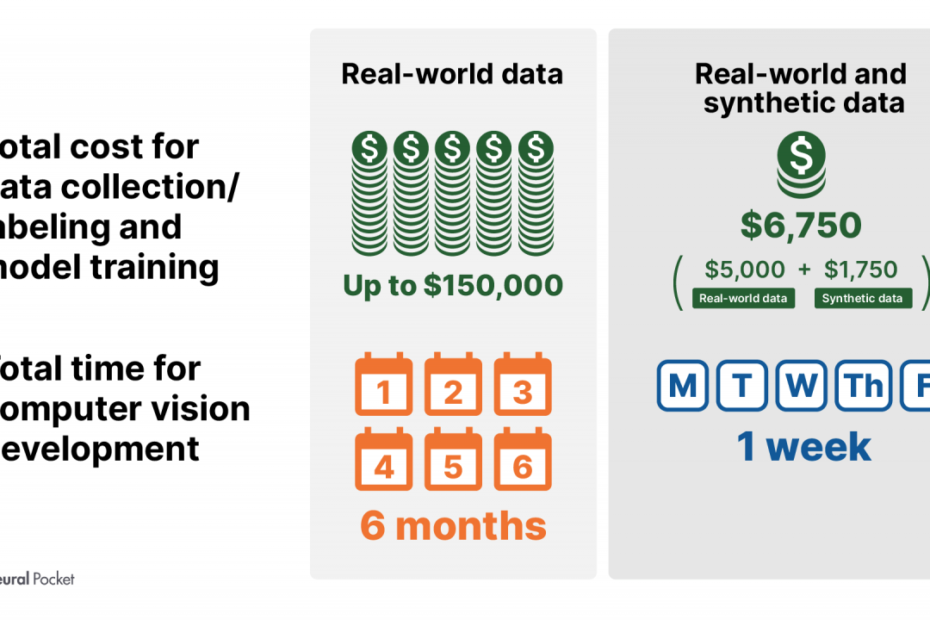
Manually collecting and labeling sufficient real-world data to train deep neural networks often takes years and millions of dollars. One study by Scale AI found that data annotation for computer vision tasks costs upwards of $60 per image.
Synthetic data generation removes these prohibitive time and monetary costs by programmatically creating massive labeled datasets. For instance, Unity shared that using synthetic data allowed them to achieve better computer vision accuracy while cutting costs and timelines by ~95% compared to manual data collection and annotation.
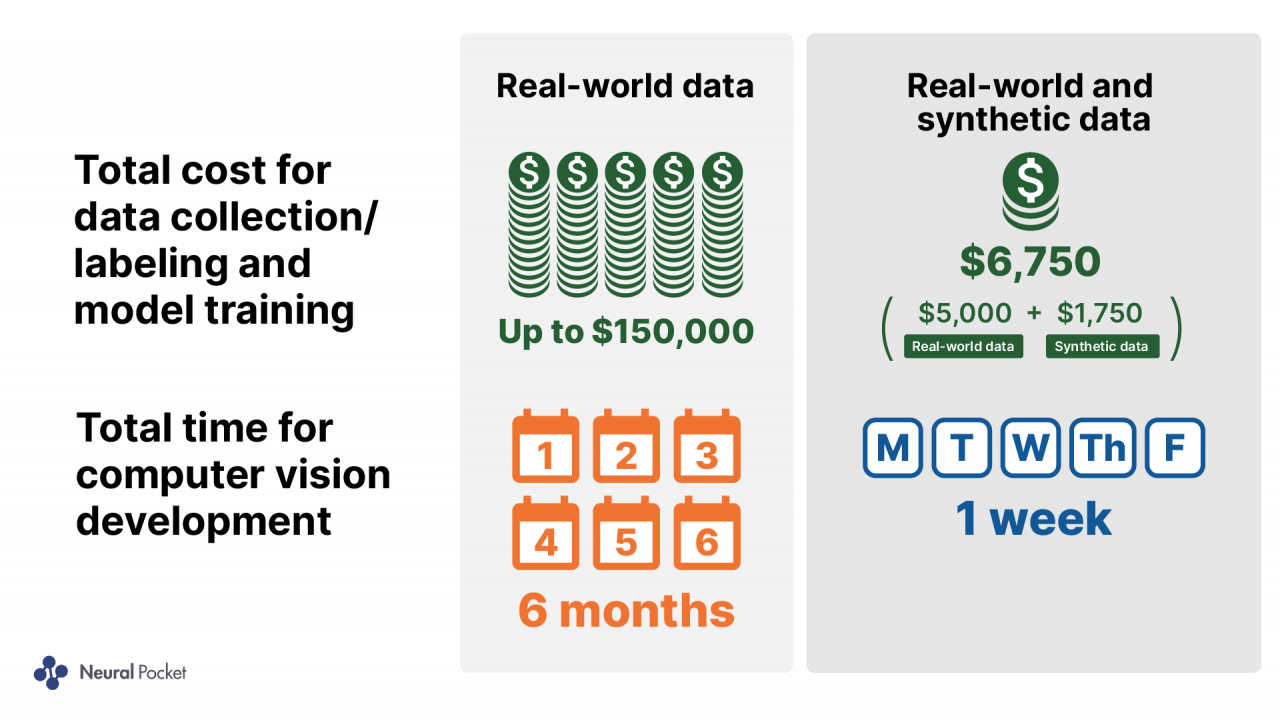
Source: Unity
Generating synthetic datasets also enables creating effectively unlimited data. If even 100,000+ labeled real-world images are prohibitively expensive, we can synthetically generate millions of data points covering edge cases.
According to an MIT study, training object detectors on just 10,000 synthetic images performs similarly to models trained on over 1 million lightly augmented real images – demonstrating the power of synthetic data scale and quality.
2. Simulate Rare Events and Edge Cases
Real-world datasets often lack sufficient examples of rare events and edge cases that are still critical for models to handle.
For instance, self-driving car vision systems need to handle accidents, but there are thankfully not enough real-world crash videos to train models effectively. Medical imaging models need to detect rare cancers and anomalies. Industrial automation needs to spot rarely occurring manufacturing defects.
With synthetic data, we can programmatically generate endless variations of these uncommon but important events to improve detection and response rates. For example, simulating diverse traffic accidents under different conditions gives self-driving AI extensive experience handling crashes safely.
One study by MRI scanner company SyntheticMR found that adding just 5% of synthetic abnormal MRI data to training sets improves brain lesion detection rates by over 24%.
3. Avoid Data Privacy Issues
Collecting real-world images and videos risks GDPR violations and data breaches even through indirect model outputs. Synthetic data generation sidesteps data privacy issues altogether by training models without real people‘s personal information.
For example, researchers were able to extract identifiable faces from pixelated images just using access to a facial recognition API – highlighting risks even from model outputs. Synthetic faces avoid this completely.
In summary, synthetic visual data unlocks game-changing advantages in developing highly accurate computer vision deep learning models cost-effectively while protecting data privacy. Let‘s look at real-world examples.
Powering Cutting-Edge Computer Vision with Synthetic Data
Many companies are already utilizing synthetic imagery and video to enhance products relying on computer vision and deep learning:
-
Caper creates smart shopping carts that recognize products using computer vision AI. They used 100-1000 synthetic images per product to train models to ~99% accuracy. This was orders of magnitude faster and cheaper than collecting and annotating real store images.
-
NVIDIA built a robotic simulation platform called Isaac Sim to train AI robots with synthetic data so they can safely transfer to real-world environments.
-
Lyft leverages synthetic data generated in the CARLA autonomous driving simulator as well as real-world data to train perception models for self-driving cars.
-
Researchers showed training object detectors on thousands of simple synthetic images with random objects significantly boosts real-world performance. The detector located objects in cluttered real scenes within 1.5 cm accuracy.
These examples demonstrate the massive opportunities synthetic visual data unlocks for computer vision systems to understand and interact with the physical world. Next, let‘s discuss the future potential as generation techniques rapidly evolve.
The Cutting Edge & Future of Synthetic Visual Data
As both machine learning and data generation methods improve, synthetic visual data will become integral to building robust computer vision models. Some promising emerging directions include:
-
Blending synthetic and real data – Strategically combining synthetic and real-world visual data can enhance model training. Recent research found this hybrid approach benefited accuracy across different model architectures.
-
Sim2real transfer – Advanced techniques like domain randomization are improving how models transfer from synthetic environments to real-world settings. More work is needed so synthetic data translates efficiently.
-
Physics-based simulation – Next-generation simulators are better modeling complex real-world physics like lighting, occlusion, and materials to generate more realistic synthetic imagery and video.
-
Generative adversarial networks (GANs) – GANs can generate synthetic data nearly indistinguishable from real-world data. Refining GAN-generated data can provide low-cost, customizable training data.
-
Personalized synthetic data – Targeted synthetic data tailored to specific models and use cases is becoming more accessible, moving beyond generic datasets.
The rapid evolution of synthetic data generation will enable previously impossible computer vision capabilities. Specialized synthetic data represents the future for efficiently developing extremely accurate models.
Realize the Potential of Synthetic Visual Data in 2024
This guide provided both a high-level overview and deep dive into how thoughtfully generated synthetic imagery, video, and 3D simulations can enable breakthrough computer vision systems.
Here are additional synthetic data resources to support your computer vision initiatives:
- Top Synthetic Data Use Cases
- Synthetic Data Generation Guide
- Synthetic Data for Deep Learning Models
- Synthetic Data Software
As you explore synthetic visual data solutions, I‘m available to consult based on my applied experience in this domain – whether clarifying approaches or reviewing provider options. Feel free to reach out with any questions:
Synthetic data unlocks game-changing potential for computer vision and deep learning models by enabling large, perfectly annotated datasets that represent edge cases. I hope this guide provided useful insights into harnessing synthetic visual data to develop the next generation of intelligent systems that can perceive and understand the world around us.
{kind=link}